Automatic Movie Review System Using Sentimental Analysis
A great article to understand the basics of sentimental analysis and data scraping by reviewing movies
In this article, we will use machine learning to perform sentimental analysis of reviews available on the IMDB website for any given movie and then decide whether to watch that film or not. It is a good project to understand the basics of NLP as well as Data Scraping. If you are in the field of machine learning for quite a long time, then most probably you can skip this tutorial.
The work-flow or methodology that we will use consists of four main parts:
- Installing all dependencies and required files
- Model Development(Naive Bayes)
- Scraping reviews of a particular movie
- Predicting the sentiment of each review and deciding whether to watch it or not.
Prerequisites
I’m assuming that you are familiar with the python programming language and you have python 3 installed in your system.
Installing required packages
You can simply use pip install pakage_name for the given packages. The packages that you need to install before start coding are:-
- selenium — for web scraping and automating the scrolling of the website. In selenium, you also need to download chomedriver.exe for using chrome automatically.
- nltk — for performing natural language processing tasks and model training.
- bs4 — for BeautifulSoup that is used for parsing HTML page.
- lxml — it is the package that is used to process HTML and XML with python.
- urllib — for requesting a web page.
- sklearn(optional) — Used for saving the trained model.
Let’s Start Coding
Create a python file for training and predicting the reviews. Don’t worry, we will scrap these reviews later in a different file.
Model Development
Firstly, we have to download all the necessary data like movie_reviews on which our model will train and some other data like stopwords, punkt that nltk have used in our code. If nltk requires some more data then it will notify you with the error. The following lines will download the data.
import nltk
nltk.download("punkt")
nltk.download("movie_reviews")
nltk.download("stopwords")
Now we will import all the required packages and files. Here, movie_reviews is our training and testing data, stopwords are words like is,the,of that does not contribute to the training. We have used shuffle for shuffling training and testing data. Naive-Bayes is the classifier mostly used for NLP(Natural Language Processing) . word_tokenizer is used to divide the text into smaller parts called tokens.
The MAIN_scrap_movies_reviews is our python file for scraping data and reviews_extract is the function that performs that task.
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
from random import shuffle
import string
from nltk import NaiveBayesClassifier
from nltk import classify
from nltk import word_tokenize
from MAIN_scrap_movies_reviews import reviews_extract
from sklearn.externals import joblib
The bag_words() takes the review and removes stopwords and punctuations from it as they don’t contribute to the training of the model and return the dictionary with every word as key and true as the value.
def bag_words(words):
global stop_words
stop_words = stopwords.words('english')
clean = []
for i in words:
if i not in stop_words and i not in string.punctuation:
clean.append(i)
dictionary = dict([word, True] for word in clean)
return dictionary
We have created the function TrainingAndTesting() that trains and check the accuracy of the model. There are two empty lists used to store positive and negative reviews. Then, we iterate in the movie_reviews column fileidsand if it contains posthen that row or review is stored in a positive review list and vice versa. After that, we iterate through each review stored in pos_reviews and call the bag_words function that in turn gives the dictionary containing review words (removed stopwords and punctuations) and associate poswith it representing that this is the positive review. The same goes for negative reviews. Then we shuffle and split the data for training and testing. We have simply used NaiveBayes classifier for this sentimental analysis. The training and testing are simple with inbuilt functions of nltk.

Training with nltk is like magic
The last line here is used to store the trained model so that there is no need to train the model every time you review the movie. Also you can simply return the classifier and use that instead in predicting phase.
def TrainingAndTesting():
pos_review = []
neg_review = []
for fileid in movie_reviews.fileids('pos'):
pos_review.append(movie_reviews.words(fileid)) for fileid in movie_reviews.fileids('neg'):
neg_review.append(movie_reviews.words(fileid)) pos_set = []
for word in pos_review:
pos_set.append((bag_words(word),'pos')) neg_set = []
for word in neg_review:
neg_set.append((bag_words(word),'neg')) shuffle(pos_set)
shuffle(neg_set)
test_set = pos_set[:200]+neg_set[:200]
train_set = pos_set[200:]+neg_set[200:] classifier = NaiveBayesClassifier.train(train_set)
acc = classify.accuracy(classifier,test_set)
print(acc)
joblib.dump(classifier,'imdb_movies_reviews.pkl')
Now we will create another file for scraping reviews from IMDB or also you can define the function in the same file.
Scraping reviews of a particular movie
Importing the required packages. Uses of all these are defined in the starting.
from selenium import webdriver
import urllib.request as url
import bs4
import time
In this function, we take the movie name as input from the user then we take the content of that particular web page using urlopen. Now we will parse the content using BeautifulSoup and find the link of the first movie result on the page and move to that link then into the comment section, click on load more comments. This is the main reason for using selenium otherwise we will stick to only 5 or 6 preloaded comments. After clicking for specific times (20) in our case, we will find the text of every review and append it into the list and return that list.
def reviews_extract():
movie = input('Enter name of movie:')
movie = movie.lower() web = url.urlopen("https://www.imdb.com/find?ref_=nv_sr_fn&q="+movie)
page1 = bs4.BeautifulSoup(web,'lxml')
b = page1.find('td',class_='result_text')
href = b.a['href']
web2 = url.urlopen("https://www.imdb.com"+href)
page2 = bs4.BeautifulSoup(web2,'lxml')
c = page2.find('div',class_='user-comments')
temp = []
for a in c.find_all('a',href =True):
g =(a['href'])
temp.append(g)
d = temp[-1]
driver = webdriver.Chrome('C:\\Users\\dell\\Desktop\\chromedriver.exe')
driver.get("https://www.imdb.com"+d)
for i in range(20):
try:
loadMoreButton = driver.find_element_by_class_name('load-more-data')
loadMoreButton.click()
time.sleep(1)
except Exception as e:
print(e)
break
web3 = driver.page_source
page3 = bs4.BeautifulSoup(web3,'lxml') e = page3.find('div',class_='lister-list') e1 = e.find_all('a',class_='title') user_reviews = []
for i in e1:
raw = (i.text)
user_reviews.append(raw.replace('\n',''))
driver.quit()
print(user_reviews)
print(len(user_reviews))
return user_reviews,movie
Predicting the sentiment of each review
After scraping, we move back to the previous python file. Now, here we will predict the sentiment of each scraped review with the already trained model. In the code, firstly we have loaded the model that we have saved earlier and also call the reviews_extract function defined above to get reviews. After that, we process every review i.e. tokenizing, remove stop words, and convert the review into the required format. Then we predict its sentiment, if it neg increases the count of n and if pos increase p and percent of positive reviews is calculated.
def predicting():
classifier = joblib.load('imdb_movies_reviews.pkl')
reviews_film, movie = reviews_extract()
testing = reviews_film tokens = []
for i in testing:
tokens.append(word_tokenize(i)) set_testing = []
for i in tokens:
set_testing.append(bag_words(i)) final = []
for i in set_testing:
final.append(classifier.classify(i)) n = 0
p = 0
for i in final:
if i == 'neg':
n+= 1
else:
p+= 1
pos_per = (p / len(final)) * 100 return movie,pos_per,len(final)
Then, in the end, we call the required functions and if the positive percentage is greater than 60%, we recommend that movie to our friends.
TrainingAndTesting()
movie,positive_per,total_reviews = predicting()
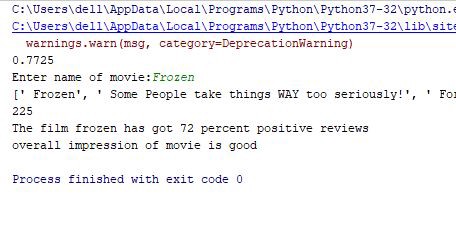
print('The film {} has got {} percent positive reviews'.format(movie, round(positive_per)))
if positive_per > 60:
print('overall impression of movie is good ')
else:
print('overall impression of movie is bad ')
My Results
I was able to get the accuracy of the model around 78% and here is the screen shot of my result. Here 225 are the number of reviews that are analyzed.
The described project is for the beginners, hence I have not used advanced techniques like RNN(Recurrent Neural Networks). The only focus of this article was to provide knowledge and starting phase projects in the field of machine learning.
Thank you for your precious time.😊And I hope you like this tutorial.
You can find the source code for the same at my Github repo.